日常运维中CPU Load高、IO高、利用率高、内存高等都是怎么处理的,思路是什么,本章简单记录下。
Linux/Unix - 平时Linux/Unix常见的各种负载都是怎么处理的?
认为一般情况下都会是哪几种情况造成的呢?
比如:
- 服务器硬件的因素,比如机房温度、CPU温度、配置等方面;
- 服务器进程,比如安装了一些服务进程、程序进程等,这些都是吃CPU资源;
- 比如Java程序,吃内存大户,最好是程序上进程控制最大使用多少内存;
- 木马病毒,僵死进程等导致CPU利用率高;
- 数据库层面,一些复杂的SQL语言、连表查、子查询、全面扫描、慢查询等;
- 磁盘IO方面比如某进程疯狂的向磁盘写入,导致整个磁盘IO高 进入wait状态的;
一般情况下,我们正常的运维场景中,现在中小型企业服务器基本上都会是云机房;
大厂/金融行业除外哈,大厂/金融据了解基本上都是自建机房,正规的机房里面,服务器的基础设施,温度等是完全不用担心的(机房划水过一年的小菜鸟)
除去了底层硬件,木马病毒的可能性也不大,云上的机器一般都会有一些安全措施,VPC、安全组、基础防护等,但是也不排除被入侵,具体还是要根据实际情况看,
另外就是我们运维中接触最多的,服务器应用程序进程,比如运维的一些基础服务,nginx mysql php,还有一些程序所提供的一些应用进程,也不排除程序出现问题导致CPU高
CPU利用率过高
模拟CPU利用率高
我这里模拟是用lookbusy模拟的,也可直接使用 单核CPU使用cat /dev/urandom | gzip -9 > /dev/null,多核心使用cat /dev/urandom | gzip -9 | gzip -d | gzip -9 | gzip -d > /dev/null
这里简单模拟下CPU百分之50,怎么处理的,其实单CPU高还是很好定位问题的,一些常见的命令即可,比如:top top -H -p pid
top
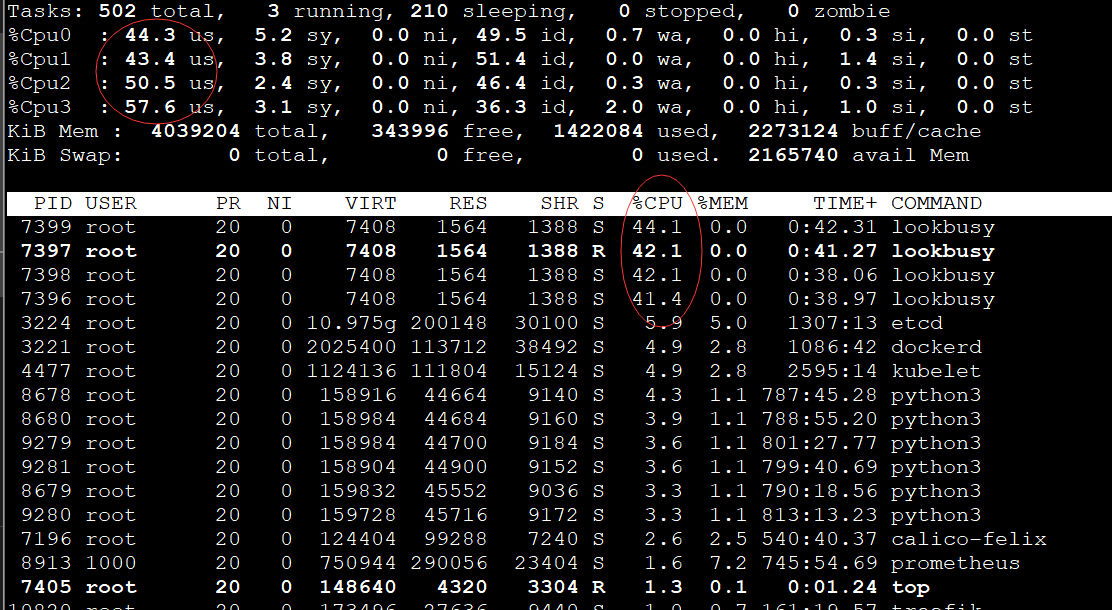
这里通过top可以看到lookbusy这个四个进程占用CPU很高,并且可以看到我4Core的CPU刚好被这四个进程跑满,接下来我们可以使用top -H -p pid具体看下这个进程有多少线程;
top -H -p 7399

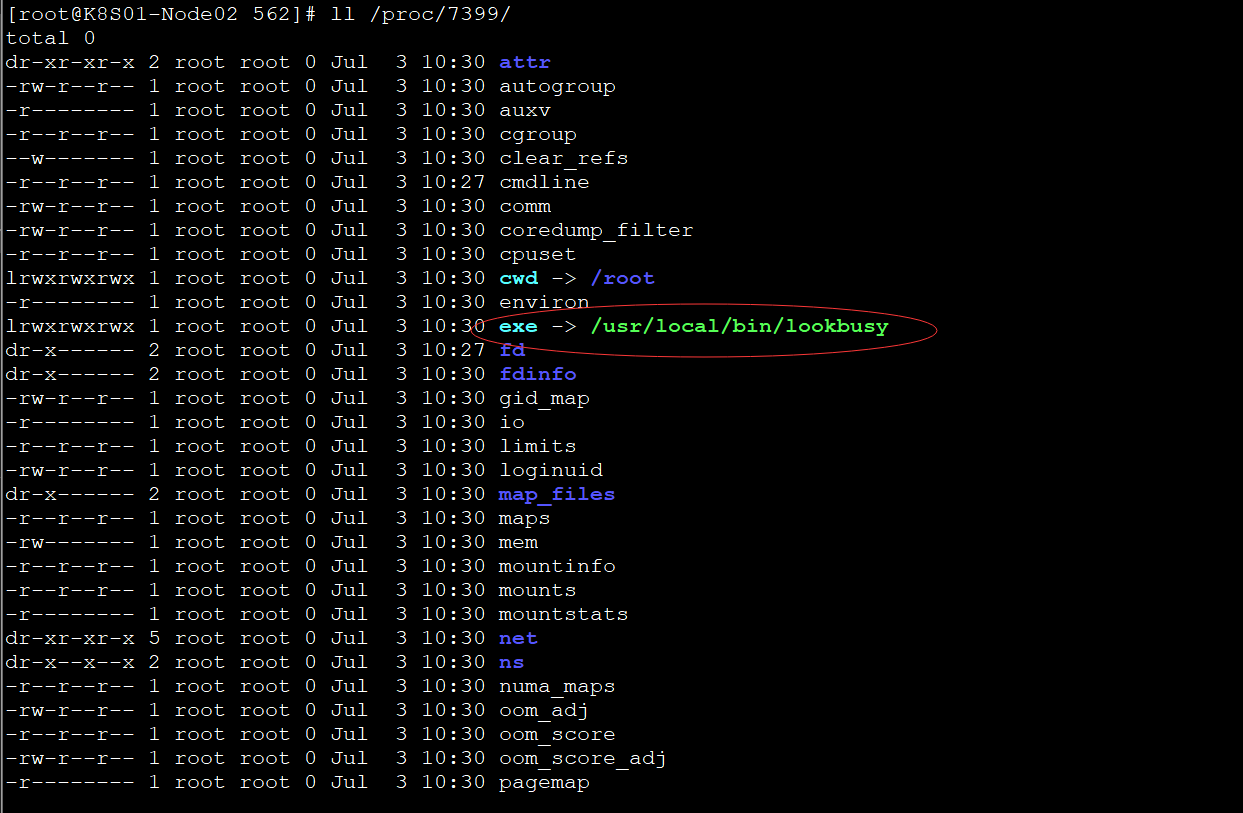
如果一个进程里面有多个线程的话,看下哪个线程比较高,单独处理那一个线程即可,如果没有多线程,就直接根据进程ID查出来对应的文件所在位置,确定是木马病毒还是程序文件,再进行下一步判断。
磁盘IO高怎么办
模拟磁盘IO
dd if=/dev/zero of=loadfile bs=1M count=1024
for i in {1..100}; do \cp loadfile loadfile1; done
模拟后top查看
- us:用户态使用的cpu时间比
- sy:系统态使用的cpu时间比
- ni:用做nice加权的进程分配的用户态cpu时间比
- id:空闲的cpu时间比
- wa:cpu等待磁盘写入完成时间
- hi:硬中断消耗时间
- si:软中断消耗时间
- st:虚拟机偷取时间

上图可以看到,CPU利用率低,Load已经开始增高了
如果发现一个机器wa过高,一般情况下都是IO高导致的
使用iostat查看
- rsec/s:每秒读取的扇区数;
- wsec/:每秒写入的扇区数。
- rMB/s:每秒中设备读取大小
- wMB/s:每秒中设备写入大小
- avgrq-sz 平均请求扇区的大小
- avgqu-sz 是平均请求队列的长度。毫无疑问,队列长度越短越好。
- await: 每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。
- %util: 在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%, 所以该参数暗示了设备的繁忙程度,一般地,如果该参数是100%表示设备已经接近满负荷运行了,当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈
[root@Yangxiaofei ~]# iostat -d -x -m 1 10
Linux 3.10.0-862.el7.x86_64 (Yangxiaofei) Thursday, July 04, 2019 _x86_64_ (6 CPU)
Device: rrqm/s wrqm/s r/s w/s rMB/s wMB/s avgrq-sz avgqu-sz await r_await w_await svctm %util
sda 0.00 0.00 0.00 5.00 0.00 0.02 8.60 1.37 139.20 0.00 139.20 114.60 57.30
sdb 0.00 0.00 0.00 880.00 0.00 439.50 1022.84 97.51 104.36 0.00 104.36 0.81 71.00
dm-0 0.00 0.00 0.00 944.00 0.00 468.44 1016.27 99.45 98.56 0.00 98.56 0.76 72.00
dm-1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-2 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-4 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
dm-3 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
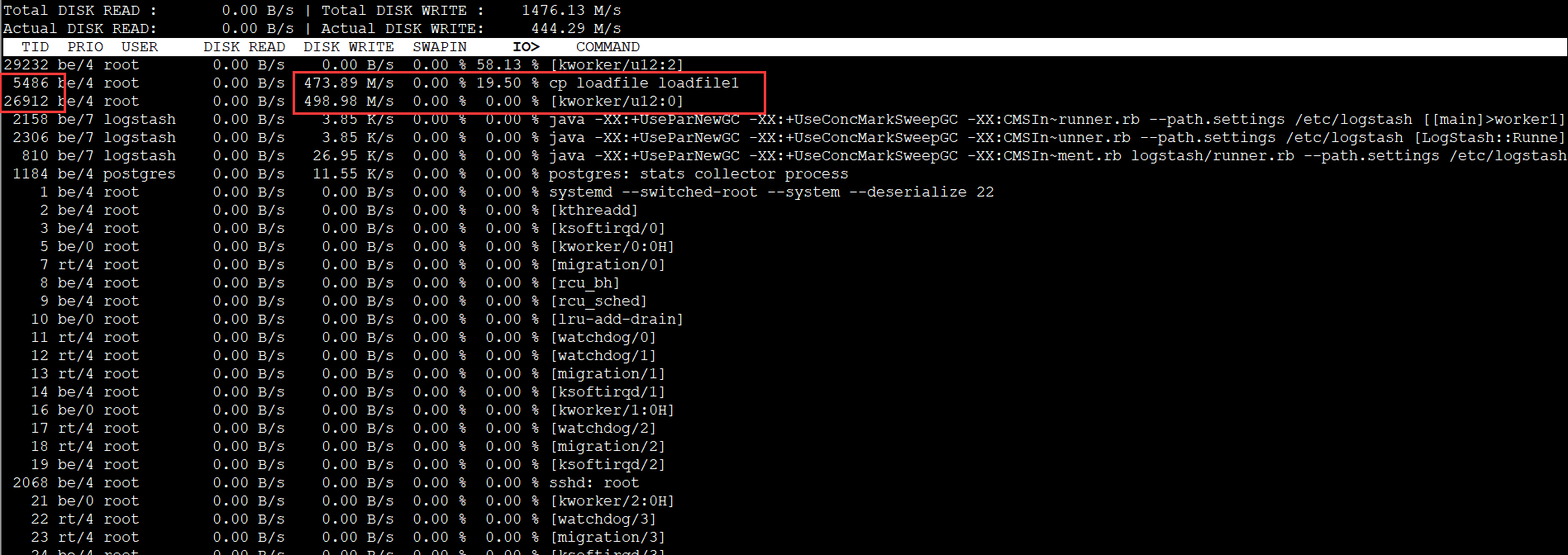
具体查看哪个进程占用的IO高,可以通过iotop命令查看哪个进程占用比较高,下图TID对应的就是top, ps aux里面的PID
CPU Load过高
一般情况下也会遇到CPU load average过高,但是CPU使用率不高,TOP里面看到load average分别是 1分钟、5分钟、15分钟;
load average怎么理解,举个例子,一条高速公路上有三个收费口,这时候正好有三辆车,这样子三个窗口都能及时处理,就不用等待,当车辆超过3,那就是需要等待,进入排队,从而引起Load过高;
比如上示例,我模拟了一个IO高,wait处理等待状态,可以看到1分钟的负载已经高了上去了,如图:
遇到这种情况一般查看
top查看哪个进程占用CPU高,排除进程引发的问题iotop查看是不是某个进行正在大量的操作磁盘IO,这时候如果有几十M/几百M每秒的要注意了mysql看是否是Mysql引起的,比如一些慢查询语言,负载的关联表/子查询等,扫描全表的SQL,阻塞的SQL等
内存过高
内存过高也可以有多个方式,比如使用top看哪个进程站内存高
理解free -m的参数意思
total used free shared buffers cached
Mem: 2005 1733 272 18 186 466
-/+ buffers/cache: 1080 924
Swap: 991 0 991
- Tocal1(表示总内存容量)
- Used1 (系统已分配的内存) userd1 = buffers1+caced1+used2
- free1 (系统未分配的内存)
- shared1(共享内存)
- buffers1 (系统已分配内存中,但未使用的buffers数量)
- cached (系统已分配内存中,但未使用的cached数量)
- used2(系统已分配的内存中,系统使用的总量)
- free2(未使用系统已分配的内存,和系统未分配内存的之和) free2 = buffers1+cached1+free1
查看占用内存最大的10个进程
ps -aux | sort -k4nr | head -n 10
Linux 释放内存, 谨慎操作
Linux释放内存的命令:
sync #释放之前sync下,防止数据丢失
echo 1 > /proc/sys/vm/drop_caches
drop_caches的值可以是0-3之间的数字,代表不同的含义:
0:不释放(系统默认值)
1:释放页缓存
2:释放dentries和inodes
3:释放所有缓存
释放完内存后改回去让系统重新自动分配内存。
echo 0 >/proc/sys/vm/drop_caches
free -m #看内存是否已经释放掉了。
